Mohammed Zniber

Data Scientist with 6 years of experience in Data collection, processing, exploration, and modelling.
View my LinkedIn Profile
Selected Projects in Data Science, Chemometrics, Applied AI and Product Optimization
Computer Vision-based Defect Detection for Augmented Reality Glasses Manufacturing
We collaborated with OptoFidelity to develop an automated defect detection workflow for augmented reality glasses using microscopy images.

Dataset:
- 644 pre-annotated microscopy images, with incomplete and inconsistent labels
- ~30 hours spent reviewing, correcting, and adding annotations
Model development:
- Trained 5 YOLO and 13 Detectron2 models with varying architectures and sizes
- Selected the model with the best recall and visual performance for validation
Deployment:
- Integrated the selected model into a Streamlit web application for automated quality inspection
Results:
- Detectron2 offers more capabilities and control compared to YOLO, though with increased implementation complexity
- Detectron2 models achieved better performance than YOLO models
- Our selected model outperforms OptoFidelity’s in-house defect detection solution
- Enabled robust, automated inspection across the dataset, improving production efficiency
Bridging the Gap between Simulation and Experiment in Antireflective Coatings: A Data-Driven Approach
We collaborated with Senop to optimize antireflective coatings in simulation and validate experiments, aligning experimental results with simulation predictions.
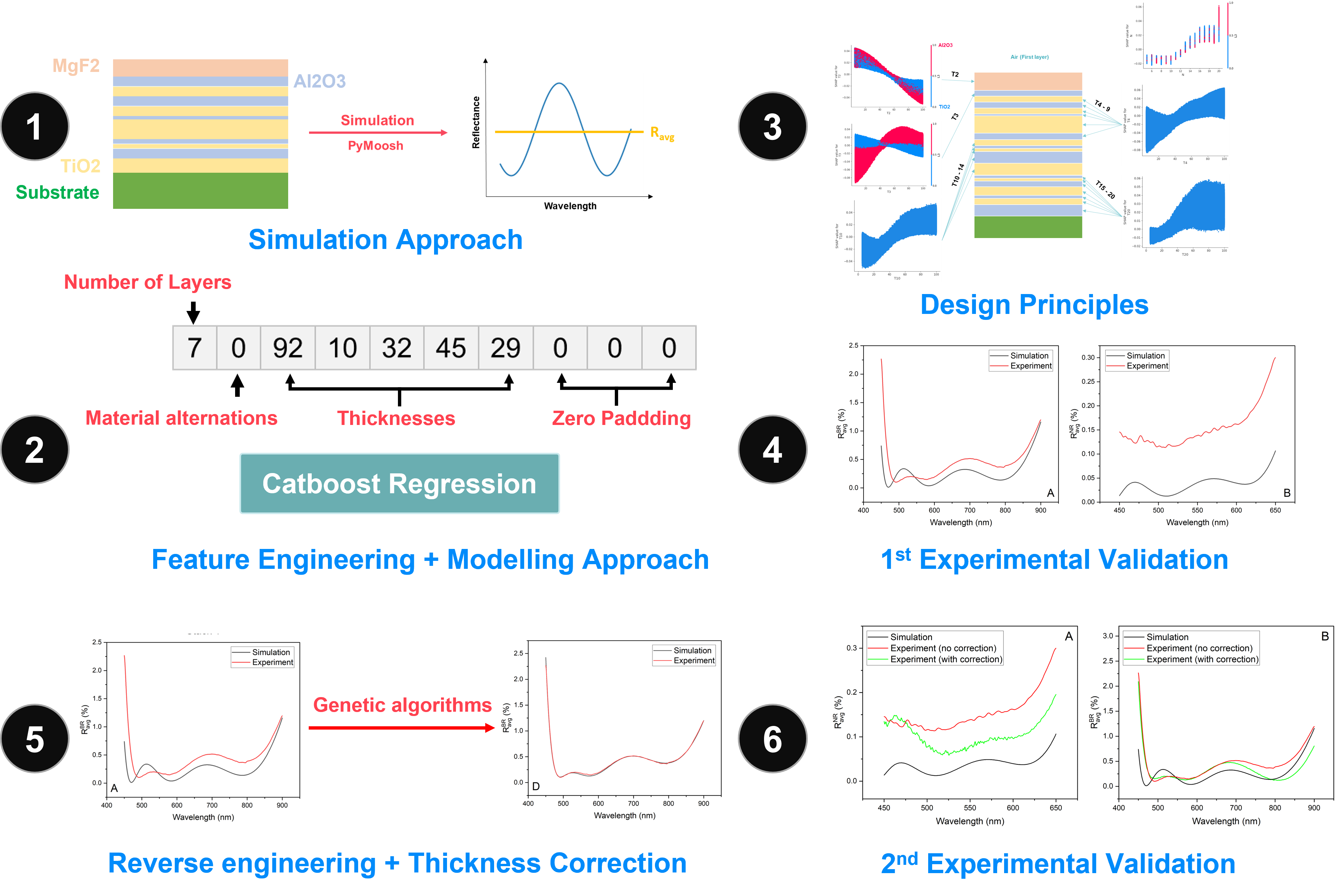
Key contributions:
- Developed a Python-based, end-to-end simulation pipeline using open-source tools, enabling high-throughput data generation while reducing licensing costs.
- Applied data analytics, feature engineering, regression modeling, and SHAP analysis to extract interpretable design principles and constrain the coating parameter space.
- Identified multiple antireflective coating stacks with ultra-low average reflectance in simulation, achieving 0.28% over a broad wavelength range (450–900 nm) and 0.04% over a narrow wavelength range (450–650 nm).
- Conducted an initial experimental validation of two optimized AR stacks using simulated thicknesses; however, the simulated performance could not be fully reproduced experimentally.
- Employed a reverse-engineering approach based on genetic algorithms to identify simulated stacks that closely match the experimental reflectance spectra, enabling estimation of the fabricated layer thicknesses.
- Derived a systematic thickness correction strategy by analyzing discrepancies between simulated and fabricated thicknesses.
- Performed a second experimental validation using the corrected thicknesses, achieving close agreement between experimental and simulated reflectance.
Results:
- Simulation: 0.28% (Stack A), 0.04% (Stack B).
- Initial experiment: 0.44% (Stack A), 0.15% (Stack B).
- After correction: 0.32% (Stack A), 0.10% (Stack B).
🔒 Proprietary project:
Code and detailed results cannot be publicly shared at the moment.
Data-driven Optimization of Laser-Assisted Bonding Process for Hybrid Integration in Silicon Photonics
We collaborated with Tampere University to optimize the laser-assisted bonding of a Si-PIC–GaSb chip by maximizing bond strength.
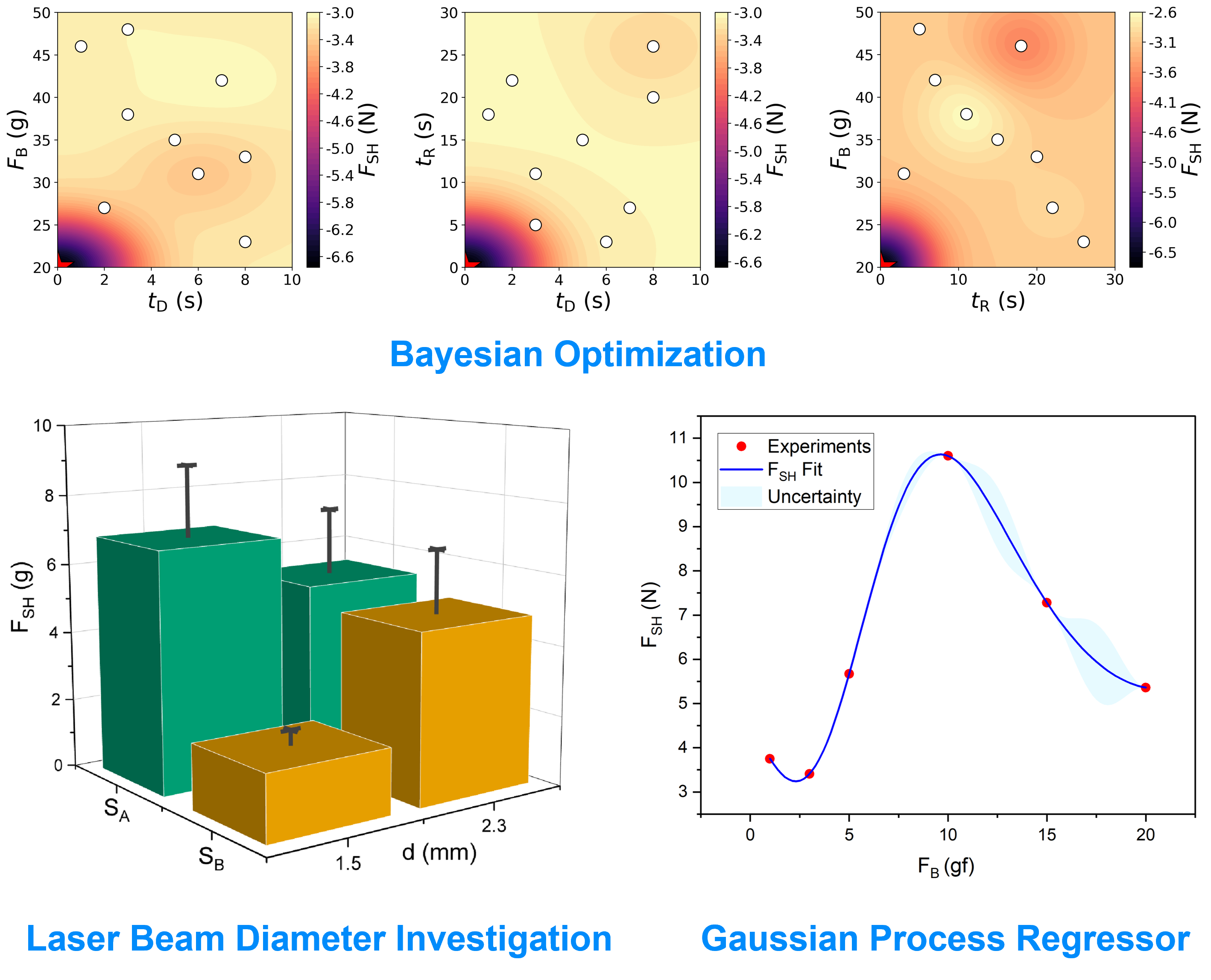
Process parameters:
- Ramp-up time (tR), dwell time (tD), bonding force (FB), laser beam diameter (d).
Objective:
- Maximize shear force (FSH), defined as the force required to break the bond.
Optimization workflow:
- Built a surrogate model mapping tR (0 - 30 s), tD (0 - 10 s), and FB (20 - 50 gf) to FSH.
- Evaluated beam diameters d = 1.5 mm and 2.3 mm.
- Refined the search in the low FB range (5 – 20 gf).
Results:
- Optimal FSH was consistently located at the bottom-left of the 2D response landscapes, defining optimal tR=0, tD=0, and FB=20.
- Two operating points were analyzed: global optimum (SA) and local maximum (SB). d = 2.3 mm showed robust performance from SA to SB, while d = 1.5 mm exhibited performance degradation when deviating slightly from the optimum.
- Gaussian Process regression in the low-force regime identified an optimal FB ≈ 10 gf.
Data-driven Optimization of Semiconductor Saturable Absorber Mirrors (SESAMs)
We collaborated with Reflekron to optimize oscillator performance and reduce experimentation by identifying optimal input parameters and chip properties for SESAMs using machine learning.

Research Questions:
- Can oscillator performance be predicted from input parameters and chip properties?
- Which input parameters and wafer properties most significantly influence performance?
Approach:
- Defined ML case studies with target outputs O3, O4.1, and O6 based on input parameters and chip properties.
- Implemented Kernel Ridge Regression (KRR) and Random Forest (RF) models, identifying the best-performing models via comparative tests.
- Performed feature importance analysis to determine which input features most strongly impact predictions and establish design rules.
- Conducted a Monte Carlo search with the best ML models to identify parameter combinations that maximize O3 and O6 while minimizing O4.1 (target ≈ 0)
Results:
- Achieved reasonable prediction errors mapping input parameters and chip properties to oscillator performance.
- RF models indicate that input parameters and chip properties are similarly informative for performance prediction.
- Feature analysis highlights key process parameters (e.g., XY chip location) as significant predictors, while the impact of chip properties is less clear.
- Generated 20 million random combinations of input parameters and chip properties to identify the combination yielding optimal oscillator performance
- Reflekron will experimentally validate the predicted best combinations and design rules, reducing trial-and-error in production.
Hackathon : Development of a Computer Vision Model for Pumps and Valves Detection
In this project, we participated in a challenge for Valmet organized by Since AI, focusing on building a complete solution for pumps and valves detection. Our team developed a web-based interface integrated with a YOLO-based computer vision model to detect and classify components in industrial environments. The work included data collection and preparation, model training, evaluation, and deployment within a user-friendly interface.

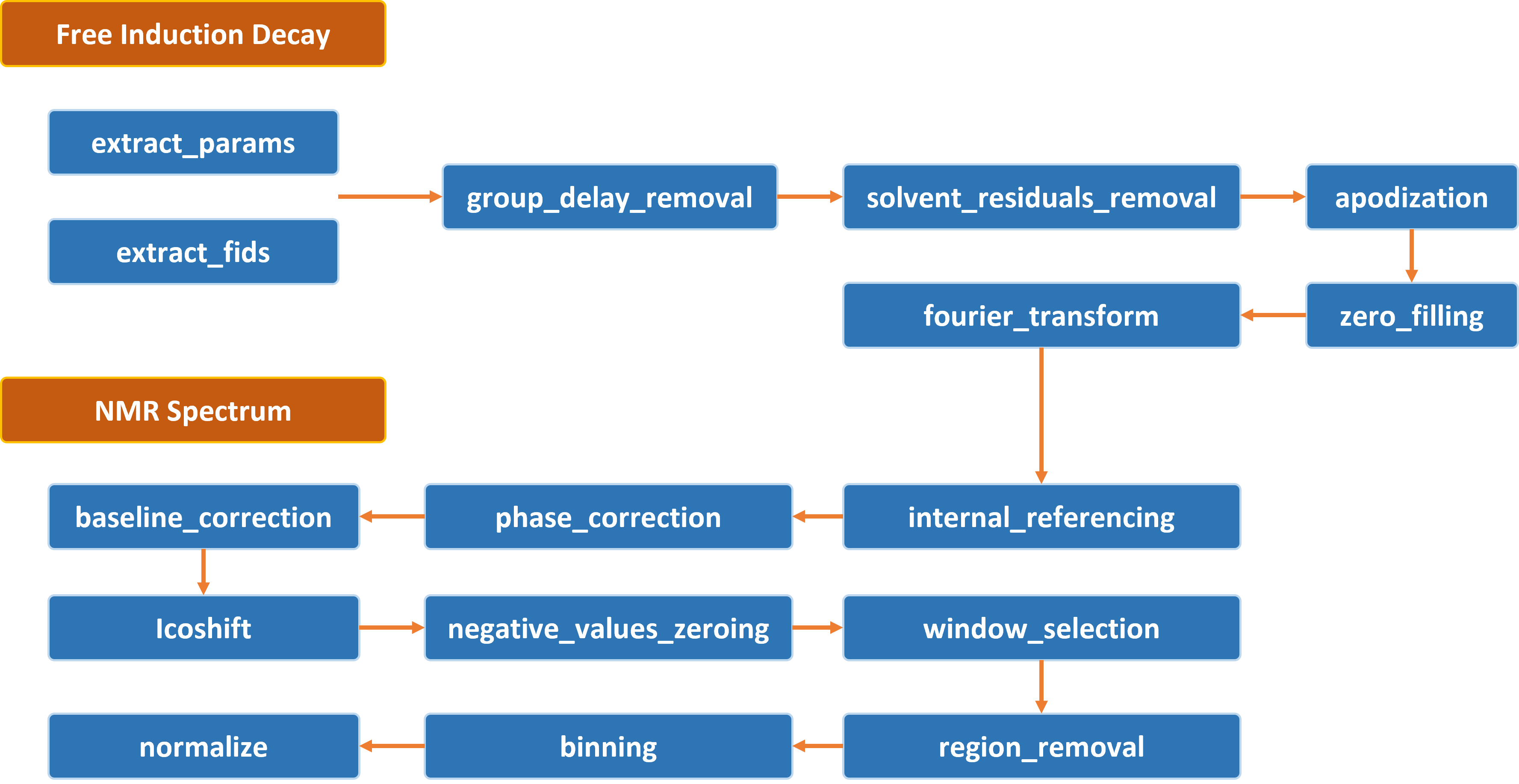
Protomix : A Python Package for 1H-NMR Metabolomics Data Preprocessing
This project focused on the development of a preprocessing pipeline for NMR data in Python. For more details, check out the scientific publication describing the package. You can also access the full documentation on ReadTheDocs and the notebook below illustrates a glimpse of the capabilities that this library has to offer.
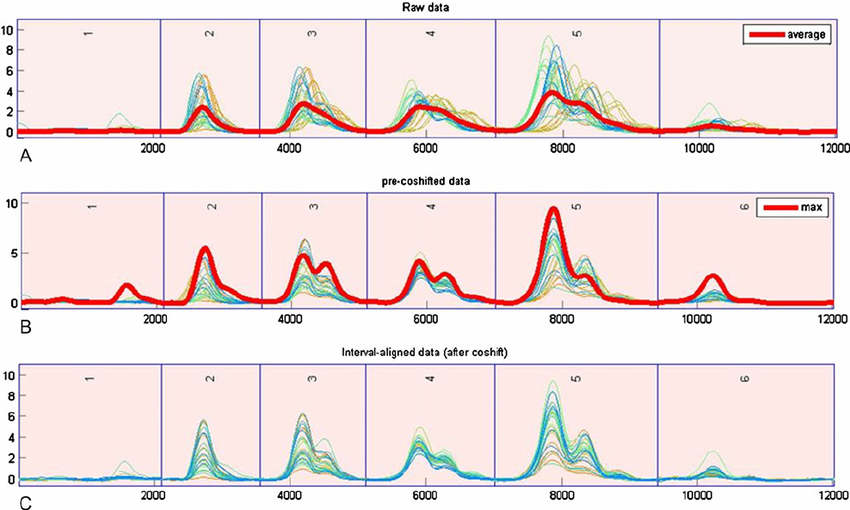
PyShift: NMR Peak Alignment using Icoshift Algorithm in Python
This project aims to implement the Icoshift algorithm in Python to achieve accurate alignment of NMR spectra. The implementation’s performance will be assessed using the Wine NMR dataset, showcasing its ability to effectively handle variations in peak positions.
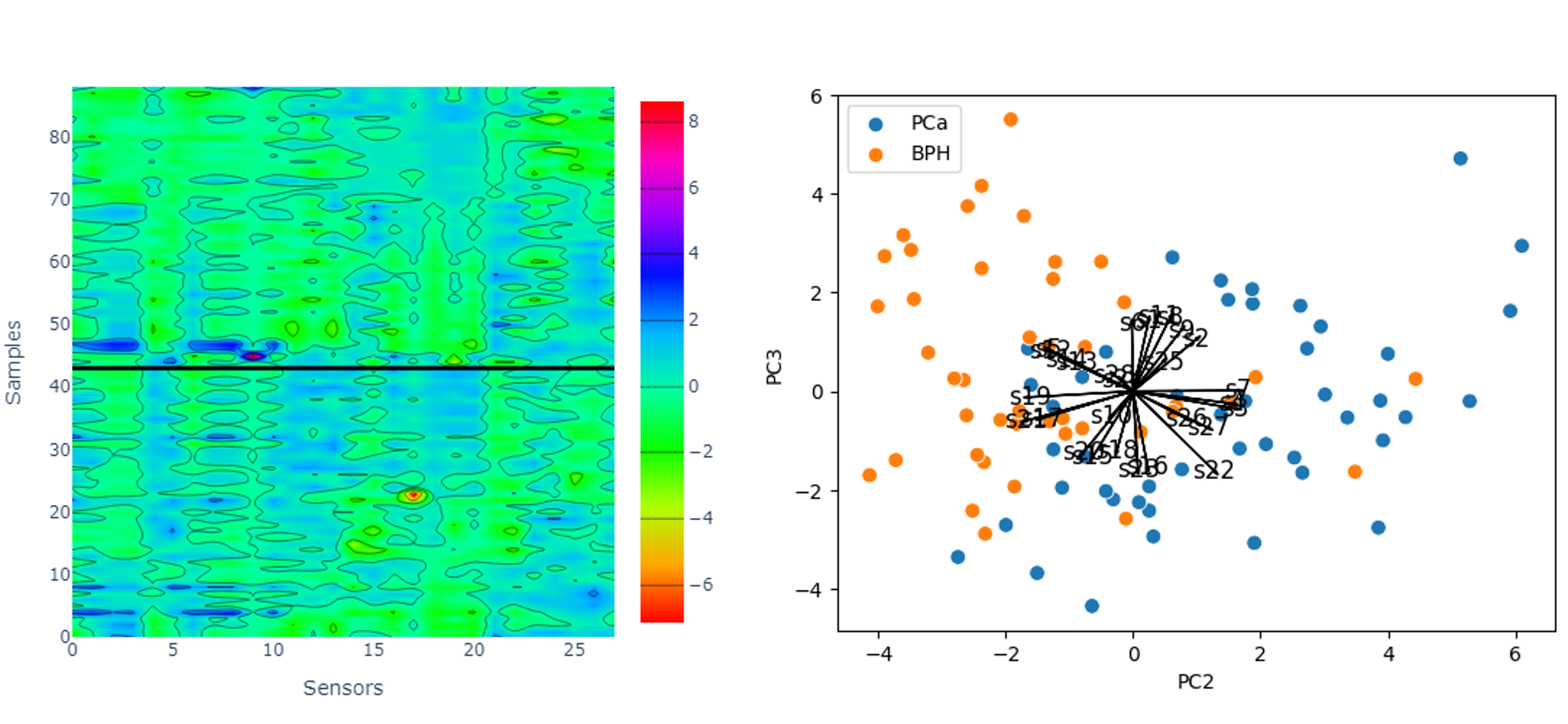
A Potentiometric Multisensor Array for Prostate Cancer Diagnosis
A potentiometric electronic tongue combined with machine learning was used to distinguish between prostate cancer patients and those with benign prostate hyperplasia by analyzing urine samples.
A Custom Data Collection Pipeline Using BeautifulSoup
The objective of this project is to utilize BeautifulSoup for gathering pertinent data and valuable insights from a rental website. This will enable users to access a comprehensive list of apartments along with their specific details. Additionally, the project includes the creation of an interactive Power BI dashboard, facilitating data visualization for a more engaging user experience.

An Interactive Power BI Dashboard for Apartments’ data
The project includes the creation of an interactive Power BI dashboard, facilitating data visualization for a more engaging user experience. The data was retrieved using BeautifulSoup in the aforementioned project.
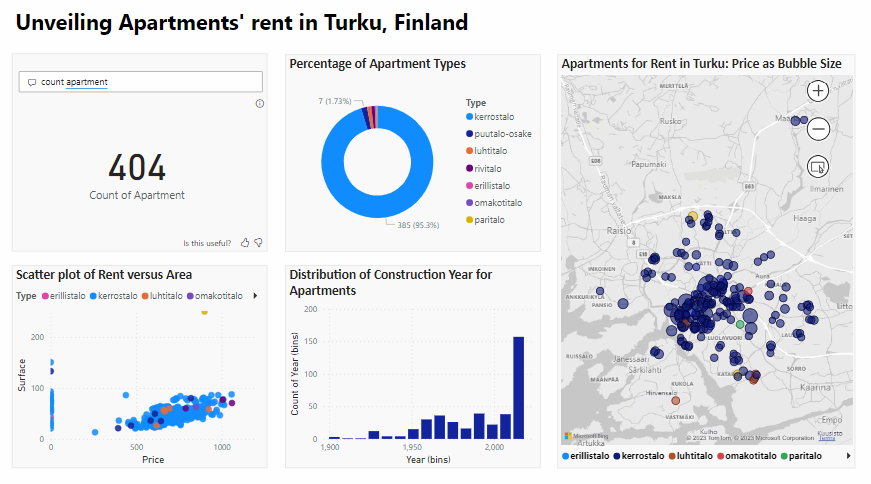
Important note: Power BI must be installed on your computer in order to interact with the dashboard.
A Comparative Analysis of Rice Varieties Osmanjik and Cameo using CatBoost Classifier and SHAPley values
This project conducts a comparative analysis of rice varieties Osmanjik and Cameo using the CatBoost classifier for accurate classification. SHAPley values are employed to interpret the model’s decisions and identify discriminative features between the two varieties.
